שיטות הדחיסה המקובלות מתחלקות באופן כללי ל-3 קבוצות עיקריות:
הראשונה, שיטת הדחיסה המשערכת, מנצלת את התלות בין ערכיהן של נקודות תמונה סמוכות.
תלות זו מבטאת את המידע העודף בתמונה (זה הניתן לדחיסה), שכן היא מאפשרת לשערך את ערך הנקודה בתמונה, בהסתמך על ערכי נקודות
התמונה שבסביבתה. אז אין צורך לשמור על ערך כל נקודה בתמונה, אלא רק על האופן שבו ניתן לקבלו כתלות בסביבתו.
שיטת הדחיסה השנייה נקראת דחיסת פיקסל, ובה כל נקודה בתמונה עוברת עיבוד בנפרד,
בלא תלות בנקודות אחרות. במקרה זה, הקוד הניתן לערכים שונים של נקודות התמונה אינו בהכרח בעל אורך אחיד, דבר המאפשר ייצוג חסכוני.
בשתי השיטות הראשונות, הקידוד מתבצע ישירות על נקודות התמונה. בשיטה השלישית, הנקראת דחיסת התמרה, דחיסת התמונה נעשית באופן בלתי ישיר. תחילה מבוצעת פעולה מתמטית על התמונה, המתמירה את מערך התמונה למערך אחר, מתאים יותר לדחיסה מאשר התמונה המקורית.
דחיסת פיקסל
הדרך הפשוטה ביותר לקידוד היא לתת לכל פיקסל ייצוג עם מספר סיביות זהה, יחסית לרמת הבהירות בו.
מקובל לייצג את רמות האפור ע"י 8 סיביות לתמונה שחור-לבן, או ע"י 8
סיביות לכל אחד משלושת הצבעים RGB בתמונה צבעונית. דרך אחרת היא ייצוג
ע"י סיבית בודדת, המשודרת בקצב גבוה. קידודים אלו, שבהם מספר הסיביות הוא אחיד לכל פיקסל, מכונים בשם הכללי קידודי
PCM. ישנן כיום שיטות חסכוניות יותר מקידוד זה.
קידוד סטטיסטי
כאשר רמות הבהירות בתמונה אינן מפולגות באופן אחיד, הגיוני להשתמש בקוד בעל אורך משתנה. חיסכון בייצוג יושג,
אם הערכים השכיחים יותר ייוצגו ע"י מספר מועט של סיביות, ואילו הערכים הפחות שכיחים ייוצגו ע"י מספר רב יותר של סיביות.
קידוד מעין זה מכונה קידוד סטטיסטי, או קידוד אנטרופיה.
כאשר באים ליישם הגיון זה, יש להבחין בשני מקרים: התמונה הרגילה (תמונת רמות אפור) ותמונת התדרים המרחביים שלה.
בתמונה הרגילה היסטוגרמת רמות האפור אינה אחידה בד"כ, אולם ההיסטוגרמה הממוצעת לטווח ארוך (כלומר, אם נבחן מספר גדול של תמונות) היא, בקירוב טוב, אחידה. במילים אחרות, לא ניתן לייחס שכיחות גבוהה לרמות אפור מסוימות. לכן, קידוד סטטיסטי אינו יעיל כשמדובר בתמונה עצמה. אולם, בתחום התדרים המרחביים המצב שונה לחלוטין. מאחר שרוב האנרגיה מרוכזת בתחום צר של תדרים נמוכים, פילוג ערכי הפיקסלים במערך ההתמרה, אינו אחיד כלל, באופן שיטתי: הערכים הגבוהים של מעט האיברים שבאזור התדרים הנמוכים, שכיחים הרבה פחות מן הערכים הנמוכים של הרוב המכריע של האיברים שמצויים מחוץ לאזור זה. לכן, קידוד סטטיסטי של מערך התמרה מתאימה יהיה יעיל מאד.
היבט מעשי אחר של שימוש בקוד סטטיסטי נוגע לאפשרות להפריד בין מילים עוקבות, ברצף הסיביות שמייצגות את התמונה המקודדת (מאחר ששוב אין כל המילים בעלות אותו אורך).
תכונה הכרחית לכל קוד שמילותיו אינן בעלות אורך אחיד היא, ששום מילת קוד אינה מהווה קידומת של מילת קוד אחרת. כלומר, מילת קוד לא יכולה להוות את החלק הראשון (משמאל) של מילת קוד אחרת.
הסיבה לכך ברורה. כאשר מילות הקוד נשמרות (או נשלחות) זו אחר זו, חייבים לדעת היכן מסתיימת מילת קוד אחת ומתחילה השנייה. אם כל מילות הקוד הן בעלות אורך זהה, ההפרדה ביניהן פשוטה. אם, למשל,
אורכה של כל מילת קוד הוא 8 סיביות, ההפרדה בין מילות קוד עוקבות נעשית ע"י מנייה. בכל פעם שמניית מספר הסיביות
הגיעה ל-8, סימן שתמה מילת קוד אחת ומתחילה הבאה אחריה.
דרך הפרדה זו אינה אפשרית כאשר מילות הקוד הן בעלות אורך שונה. אז התנאי ההכרחי להפרדה בין מילות קוד עוקבות הוא שאין מילת
קוד המהווה קידומת למילת קוד אחרת.
קידוד הופמן
אלגוריתם הקידוד של הופמן (שהוצע בשנת 1962)
מאפשר לייצג באופן חסכוני את רמות הבהירות השונות, על פי מידת שכיחותן,
תוך קיום אילוץ ההפרדה בין מילות הקוד.
כבסיס ליצירת קוד הופמן של תמונה מסוימת (שמיוצגת על ידי סדרת מספרי בהירויות הפיקסלים), נתונות השכיחויות של רמות הבהירות בתמונה.
אם נתון, למשל, שהשכיחות של רמת בהירות A היא 0.25, פירוש הדבר שרבע מנקודות התמונה הן בעלות ערך A.
תהליך יצירת קוד הופמן שקול לבניית עץ בינארי, אשר צמתיו הם רמות הבהירות השונות. בכל שלב בבניית העץ נוסף לו צומת חדש ע"י איחוד שני הצמתים בעלי השכיחות הנמוכה ביותר. השכיחות של הצומת החדש שווה לסכום השכיחויות של שני הצמתים שהתאחדו. אחרי ששני צמתים אוחדו, שוב אין מתייחסים לשכיחותיהן, אלא לשכיחת הצומת שנוצר כתוצאה מאיחודם (ואליו מתייחסים כאשר בוחרים את שני הצמתים בעלי השכיחות הנמוכה ביותר בשלב הבא).
בניית עץ הקוד של הופמן מסתיימת אחרי שכל הצמתים אוחדו. הקוד עצמו מתקבל מן העץ על ידי הצבת '0'
ו-'1' לשתי התפצלויות מכל צומת. אין חשיבות לסדר ההצבה, כלומר אפשר להציב '1'
להתפצלות הימנית ו-'0' לשמאלית, או להפך (אך בכל מקרה יתקבל קוד שונה).
הקוד עבור רמת בהירות A הוא אוסף הסיביות על הענפים המחברים את שורש העץ אל הצומת של
הרמה A. חשוב להדגיש שקוד הופמן אינו יחיד, וקיימות אפשרויות שונות לבנות אותו עבור תמונה נתונה
(כלומר ישנם עצים אפשריים שונים).
היעילות של קידוד הופמן לסדרת מספרים נתונה (כלומר, יחס הדחיסה שניתן לקבל) גדלה ככל שמספר הרמות בסדרה המקורית גדול יותר,
וככל שהבדלי השכיחויות בין הרמות השונות גדולים יותר.
ולהפך: בסדרה שבה הרמות השונות מופיעות בשכיחויות דומות, אין טעם לבצע קידוד הופמן, משום שלא תתקבל דחיסה משמעותית, ויתרה מכך -
לעיתים כמות הסיביות הדרושה לייצוג הסדרה אף תגדל.
קידוד Run-length (RLE)
בשטחי תמונה, שבהם רמת הבהירות משתנה באופן מתון (תדירויות מרחביות נמוכות), יהיו קטעים רצופים שבהם ערכי הפיקסלים זהים. במקום לציין בייצוג מלא את כל ערכי הפיקסלים הזהים, די במקרה זה לציין את ערך הפיקסל הראשון בקבוצה, ואת מספר הפיקסלים העוקבים בעלי אותו ערך. קידוד כזה נקרא קידוד Run-Length (ובקיצור RLE).
הקידוד נעשה תוך סריקה אופקית של שורות התמונה, והוא מחליף את רצף הפיקסלים בשורה באוסף הזוגות
(g1, l1),
(g2, l2),...,(gk, lk),
כאשר gi מייצג את ערך הפיקסל הראשון בקבוצה, ו-li מציין את מספר הפיקסלים בעלי אורך זהה
הבאים בעקבותיו.
נסה לקודד את ה"פיקסלים" הבאים:
קוד RLE יעיל, למשל, בקידוד של מפות מזג אוויר או תמונות לווין של שטחים נרחבים. במקרים האלה, ניתן לצפות להשתנות
מתונה של רמות הבהירות ולאותה בהירות בקטעים שלמים.
השימוש בקידוד RLE יעיל במיוחד לתמונות בעלות שני ערכים (תמונה בינארית),
כמו תמונת פקסימיליה. במקרה זה, אין צורך לציין את ערך הפיקסל הראשון בכל קבוצת ערכים אלא רק לציין את ערך הנקודה הראשונה בכל שורה ואת
אורכי הקבוצות כלומר: g1, l1, l2, ...., lk. מייצוג זה ברור,
ש-l1 פיקסלים הם בעלי אורך g1 כלומר 1
או 0 , אחריהם יהיו l2 פיקסלים בעלי ערך הפוך (0 אם
g1 = 1, אם g1 = 0 אז 1),
קבוצה באורך g3 פיקסלים בעלי אורך זהה ל-g1, וכן הלאה.
ברור גם, כי לתמונה לא בינארית, הכוללת שטחים בעלי תדר מרחבי גבוה (השתנות מהירה של רמות הבהירות), קידוד RLE
אינו יעיל. אם, לדוגמה, הבהירות משתנה עם כל פיקסל לאורך השורה, יידרש מספר סיביות כפול לייצוגה בעזרת קוד RLE,
לעומת ייצוג כל פיקסל בנפרד. זאת משום שבנוסף לערך הפיקסל, מצוין לידו גם אורך הקבוצה, שבמקרה זה הוא 1.
לבסוף, ניתן להעביר תמונה דחוסה בקידוד RLE, בקוד הבנוי ממילים בעלות אורך אחיד
(PCM) או ממילים בעלות אורך משתנה
(למשל, בקידוד הופמן). האפשרות השנייה יותר יעילה בד"כ, משום שנוסף בה שלב שני של דחיסה.
דחיסה משערכת
במרבית התמונות קיים מתאם מרחבי גבוה בין ערכי נקודות סמוכות בתמונה. מעברים חדים מוגבלים לקווי
גבול בין חלקים שונים בתמונה. לכן, הערך של כל נקודה בתמונה קרוב בד"כ לערכי שכנותיה בתמונה. במילים אחרות, ההפרשים בין נקודה אחת
לשכנותיה הם בד"כ קטנים ביחס לערך הנקודה עצמה.
אפשר לנצל את התכונה הזו לדחיסה, ע"י ייצוג התמונה באמצעות ההפרשים בה, ולא באמצעות ערכי הנקודות (הצורה הרגילה לייצוג). בעת פריסת התמונה
הדחוסה, משערכים את ערכה של כל נקודה (כלומר, מנבאים את ערכה) מתוך ערכי אותן נקודות שכנות, שערכיהן כבר קבועים. שיטת הדחיסה הזו נקראת
דחיסה משערכת.
הדרך הפשוטה והמהירה ביותר לדחוס בשיטה זו היא לשערך כל נקודה עפ"י ההפרש בינה לבין קודמתה. דחיסה כזו נקראת דחיסת PCM הפרשי, או דחיסת DPCM.
מאחר שבממוצע ערכי ההפרשים קטנים בהרבה מן הערכים של נקודות התמונה, נדרשות פחות רמות לייצוג התמונה ע"י הפרשים, ולכן - גם מספר מועט יותר של סיביות. לכן, במקום לשמור (או לשדר) את ערכי הנקודות עצמן, עדיף לשמור (או לשדר) את ערכי ההפרש בין נקודות סמוכות. הדרך הפשוטה ביותר לעשות זאת היא בעזרת חישוב ההפרש בתמונה המקורית בין כל נקודה לקודמתה, כלומר
כאשר הוא ערך הנקודה, m ו- n הם מספרי השורה והעמודה ו- e הוא ערך ההפרש. במקרה כזה ערכי הנקודות בתמונה המשוערכת (או הפרוסה) - שנסמנן ע"י בשורה מסוימת, m , יתקבלו כך:
וכן הלאה.
פריסה מדויקת של ערכי הנקודות בתמונה, מתוך ערכי ההפרש e, מותנה בייצוג מלא ומדויק של ערכי e.
מאחר שתחום הערכים האפשרי של e הוא [255 -255], כלומר כפול מתחום ערכי נקודות התמונה, לא רק שאין דחיסה,
אלא ההפך מכך: יש לייצג את e ע"י 9 סיביות במקום 8.
כדי לקבל דחיסה, יש לכמות את ההפרש e באמצעות מספר קטן ככל האפשר של סיביות.
את ההפרש המכומה נסמן ע"י . נניח, למשל, שמכמים את ההפרש באמצעות
3 סיביות (ובכך מאפשרים את דחיסת התמונה ביחס 8:3) אופן הקצאת הסיביות הללו לכימוי ההפרש
הוא בעל חשיבות רבה: ראשית, יש לחלק את התחום לשניים, מחצית חיובית ומחצית שלילית. שנית, יש לקבוע את אופן הכימוי: אם ,למשל,
כל רמת אפור בייצוג ההפרשי זהה לרמת אפור בתמונה המקורית, אזי ההפרש בין זוג נקודות סמוכות
מוגבל לתחום [4,-4] (בעזרת 3 סיביות ניתן לייצג 8 ערכים). מגבלה זו יוצרת בעיה
במקומות שבהם מעברי בהירות חדים בתמונה, שבהם ההפרש המכומה רווי ואינו מייצג את מלוא השינוי האמיתי בתמונה.
ניתן להתגבר על בעיה זו ע"י כימוי גס יותר של ההפרשים או ע"י יצירת אי אחידות בקצה התחום, שתאפשר קפיצות גדולות יחסית.
אולם, גם שיפור הכימוי מהווה פתרון חלקי בלבד. אם, למשל, מתרחשת קפיצת מדרגה של 50 רמות אפור בנקודה מסוימת,
הרי גם כימוי לא אחיד לא יעזור. לכן משנים את אופן חישוב ההפרש: במקום לחשבו בין שתי נקודות עוקבות בתמונה המקורית, מחשבים בכל
רגע את ההפרש בין הערך האמיתי של כל נקודה בתמונה המקורית לבין ערך הנקודה הקודמת בשורה, כפי שהוא אמור להתקבל בתמונה המשוערכת
(מחישוב ההפרשים). להלן מתואר תרשים של המערכת:
מערכת לדחיסה ופריסה בשיטת DPCM. סימול ה"כובע" על ערך התמונה f מייצג ערך משוערך





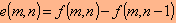
 הוא ערך הנקודה, m ו- n הם מספרי השורה והעמודה ו- e הוא ערך ההפרש. במקרה כזה ערכי הנקודות בתמונה המשוערכת (או הפרוסה) - שנסמנן ע"י
הוא ערך הנקודה, m ו- n הם מספרי השורה והעמודה ו- e הוא ערך ההפרש. במקרה כזה ערכי הנקודות בתמונה המשוערכת (או הפרוסה) - שנסמנן ע"י 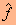 בשורה מסוימת, m , יתקבלו כך:
בשורה מסוימת, m , יתקבלו כך: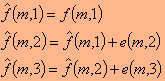

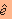 . נניח, למשל, שמכמים את ההפרש באמצעות
3 סיביות (ובכך מאפשרים את דחיסת התמונה ביחס 8:3) אופן הקצאת הסיביות הללו לכימוי ההפרש
הוא בעל חשיבות רבה: ראשית, יש לחלק את התחום לשניים, מחצית חיובית ומחצית שלילית. שנית, יש לקבוע את אופן הכימוי: אם ,למשל,
כל
. נניח, למשל, שמכמים את ההפרש באמצעות
3 סיביות (ובכך מאפשרים את דחיסת התמונה ביחס 8:3) אופן הקצאת הסיביות הללו לכימוי ההפרש
הוא בעל חשיבות רבה: ראשית, יש לחלק את התחום לשניים, מחצית חיובית ומחצית שלילית. שנית, יש לקבוע את אופן הכימוי: אם ,למשל,
כל 







