8. מבני חיפוש
מבנה נתונים
ואלגוריתמים
לפני שנבחן
מספר שיטות חיפוש, אנו צריכים להתייחס למספר פעולות על עצים, ובמיוחד לפעולות של
מעבר על עצים.
פעולות
על עץ
ניתן לעבור על
עץ בינארי במספר דרכים:
|
1. בקר בשורש. .2. עבור על
תת-העץ השמאלי .3. עבור על
תת-העץ הימני |
pre-order |
|
1. עבור על תת-העץ השמאלי. 2. בקר בשורש. .3. עבור על
תת-העץ הימני |
in-order |
|
1. עבור על תת-העץ השמאלי. 2. עבור על תת-העץ הימני. 3. בקר בשורש. |
post-order |
אם נעבור על עץ
בינארי המסודר בצורה סטנדרטית, בשיטת in-order,
אזי נבקר בכל הצמתים בסדר ממוין.
עצי חישוב (parse trees)
אם נייצג כעץ
את הביטוי:
A * ( ( ( B + C ) * ( D * E ) + F ),
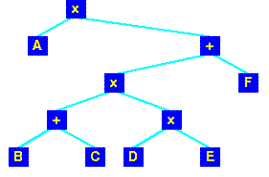 העץ יראה כך:
העץ יראה כך:
אם אחר כך נעבור
על העץ ב- post-order נקבל: A B C + D E * * F + .
ברישום הביטוי
באופן כזה - סימון "פולני-הפוך", נעשה שימוש במהדרים במטרה לחשב ערכי
ביטויים.
עצי
חיפוש
ראינו כיצד
משמשת ערמה על מנת לשמר עץ מאוזן
עבור תור קדימויות. מה בנוגע לעץ שבו מאוחסן מידע שאותו רוצים לשלוף מהעץ (אך לא
להסירו)? אנו מעונינים ביכולת למצוא פריט במהירות בעץ כזה על פי ערך המפתח שלו.
שגרת החיפוש על עץ בינארי היא:
tree_search(tree T, Key key) {
if (T == NULL) return NULL;
if (key == T->root) return T->root;
else
if (key < T->root) return tree_search( T->left, key );
else return tree_search( T->right, key );
}
כך באופן פשוט,
מסופק זמן חיפוש של O(logn) כל עוד אנו שומרים על העץ מאוזן. אולם,
אם פשוט נוסיף
פריטים לעץ, יתקבל עץ לא מאוזן:
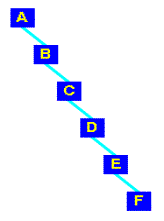
זה מה שיקרה אם
נוסיף את האותיות:
A B C D E F לפי סדר זה לעץ:
ניתן לראות
שאין זה בדיוק עץ מאוזן!
מושגים
מעבר
על עץ ב- Pre-order
מעבר על עץ בסדר הבא: שורש, שמאל, ימין.
מעבר
על עץ ב- In-order
מעבר על עץ בסדר הבא: שמאל, שורש, ימין.
מעבר
על עץ ב- Post-order
מעבר
על עץ בסדר הבא: שמאל, ימין, שורש.
המשך ל: עצי
אדום-שחור חזור
ל: תוכן עניינים