9.3 עצי חיפוש בינאריים אופטימליים
מבנה נתונים
ואלגוריתמים
עד עכשיו הנחנו
כי עץ חיפוש אופטימלי הוא עץ שבו ההסתברות להגיע לכל המפתחות היא שווה (או אינה
ידועה, ובמצב כזה אנו מניחים שהיא שווה). לכן התמקדנו באיזון העץ כדי שעלות מציאת
מפתח תהיה לכל היותר log n..
בכל אופן, חשוב
על מילון של מילים שתוכנת הגהה של מסמכים בשפה האנגלית עושה בו שימוש. התוכנה תבצע
פעמים רבות יותר חיפוש של מילים כגון: 'a',
'the', 'and',
מאשר של מילים לא נפוצות. מילון זה חייב להיות גדול: לאדם המשכיל הממוצע יש אוצר
מילים של כ- 30,000 מילים, ולכן מילון כזה צריך להכיל כ- 100,000 מילים בכדי להיות
יעיל. בנוסף, קל ליצור טבלת שכיחויות של הופעת המילים: המילים פשוט נספרות במדגם
כלשהו של מסמכים שאמור לייצג את כלל המסמכים האמורים להיבדק. יתכן שבשורש של עץ
בינארי תהינה מילים לא שכיחות כגון 'miasma',
דבר שיגרום לכך שביותר מ- 99.99 אחוז מהחיפושים, תבוזבז לפחות השוואה אחת.
אם מפתח k הוא בעל שכיחות יחסית rk,
אזי בעץ אופטימלי נקבל:
sum(dkrk)
כאשר dk הוא המרחק של המפתח k
מהשורש (כלומר, מספר ההשוואות שחייבות להתבצע
לפני מציאת k).
אנו עושים
שימוש בתכונה הבאה:
למה
תתי-העצים של עצים אופטימליים הם בעצמם עצים
אופטימליים.
הוכחה
אם תת-עץ של עץ חיפוש איננו עץ אופטימלי, אזי עץ חיפוש
טוב יותר ייווצר אם תת-העץ יוחלף בעץ אופטימלי.
לכן הבעיה היא
לקבוע איזה מפתח ימוקם בשורש העץ. ההליך יכול לחזור על עצמו עבור תתי-העצים הימני והשמאלי.
בכל אופן, בגישת הפרד ייבחר כל מפתח כשורש פוטנציאלי וההליך יחזור לכל תת-עץ. מאחר
שיש n אפשרויות בחירה עבור השורש ו- 2*O(n) אפשרויות בחירה עבור השורשים של תתי-העצים, מתקבל
אלגוריתם של O(nn).
ניתן ליצור
אלגוריתם יעיל על ידי הגישה הדינאמית. נחשב את O(n)
העצים הטובים ביותר המורכבים משני פריטים בלבד (השכנים ברשימה ממוינת של מפתחות).
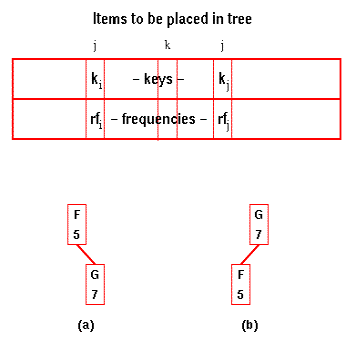
בתרשים ישנם
שני סידורים אפשריים
עבור עץ המכיל
את F ו- G.
העלות עבור (a) היא:
5*1 + 7*2 = 19
ועבור (b):
7*1 + 5*2 = 17
לכן (b) הוא העץ האופטימלי ועלותו
נשמרת כ- c(F,G). G גם נשמר כשורש
של תת-העץ F-G הטוב ביותר ב- (F,G)
טוב ביותר.
באופן דומה
ניתן לחשב את העלות הטובה ביותר עבור כל n-1 תתי-העצים עם שני הפריטים c(g,h), c(h,i), וכדומה.
בתתי-העצים
המכילים שני פריטים משתמשים לחישוב העלות הטובה ביותר עבור תתי-עצים
בעלי שלושה
פריטים. הליך זה נמשך עד אשר מחושבים העלות והשורש של עץ-החיפוש האופטימלי בעל n פריטים.
ישנן O(n2) עלויות כאלה של תתי-עצים. כל אחת דורשת n פעולות כדי לקבוע האם עלות
תתי-העצים
הקטנים יותר ידועה.
לכן האלגוריתם
הכללי הוא O(n3).
לחץ כאן על לטעון קוד של עץ חיפוש בינארי אופטימלי
שים לב לשימוש
במספר 'טריקים' של C בכדי להקצות דינאמית
מערכים דו-ממדיים תוך שימוש ב-קדם-מעבדים (pre-processor)
גדולים עבור C ו- BEST!
קוד Java עשוי להיות קל יותר להבנה. קוד זה עושה שימוש ב- מטריצות ערכים שלמים (integer matrices). מבני נתונים אלה יכולים להיות
מיוצגים באופן הבא:
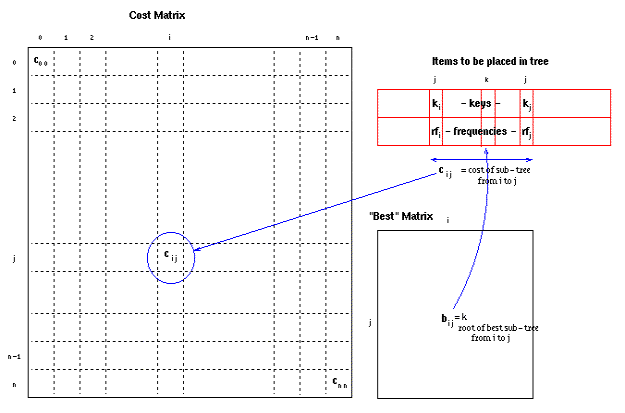
לאחר הצעדים
הראשוניים, מבני הנתונים שבהם משתמשים מכילים שכיחויות rfi ב- cii(העלות
של עצים בעלי פריט אחד), ערכי max בכל מקום מתחת לאלכסון ואפסים בכל מקום מעל
לאלכסון (על מנת להביא בחשבון עצים שאינם בעלי ענף ימני או שמאלי):
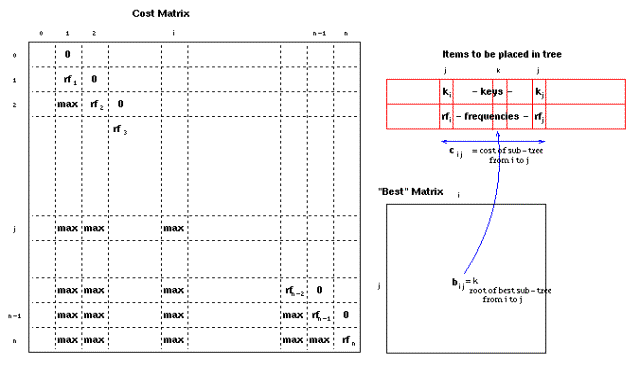
באיטרציה
הראשונה כל המקומות שמתחת לאלכסון (ci,i+1) יתמלאו בעלויות האופטימליות של עצים בעלי שני פריטים
מ- i ל- i+1..
באיטרציות
הבאות העלויות האופטימליות של עצים בעלי k-1 פריטים (ci,i+k) ממולאים תוך שימוש בחישובי העלויות הקודמים של עצים
קטנים יותר.
|
|
|
המשך ל: כפל שרשרת מטריצות חזור
ל: תוכן עניינים