3.2 רשימות
מבנה נתונים
ואלגוריתמים
ליישום שבו
נעשה שימוש במערך יש חסרון אחד בולט: חובה לדעת את המספר המקסימלי של נתונים שבהם
יש לטפל כבר בשעת יצירת המערך.
דבר זה יוצר
בעיה בתוכניות שבהם מספר הנתונים המקסימלי אינו ניתן לניבוי מדויק כבר בעת כתיבת
התוכנית. למרבה המזל, ניתן להשתמש במבנה נתונים הנקרא רשימה מקושרת, כדי להתגבר
בעיה זו.
3.2.1 רשימות מקושרת
הרשימה המקושרת
היא מבנה נתונים דינאמי גמיש ביותר: נתונים יכולים להתווסף או להימחק ממנה ללא
כל בעיה. התוכניתן אינו צריך לדאוג בנוגע לכמות הנתונים שעימה התוכנית תצטרך
להתמודד. דבר זה מאפשר לו לכתוב תוכניות חזקות, אשר דורשות פחות אחזקה. מקור נפוץ
לבעיות באחזקת תוכניות הוא הצורך להגדיל את קיבולת התוכנית, כך שתוכל להתמודד עם
כמות נתונים גדולה יותר. אפילו ההערכה הנדיבה ביותר לגדילה פוטנציאלית של כמות
הנתונים בעתיד, מתגלה לעיתים כלא מתאימה.
ברשימה מקושרת,
לכל נתון מוקצה מקום בעת כניסתו לרשימה. בנוסף, נשמר קשר בין כל נתון לנתון שאחריו
ברשימה.
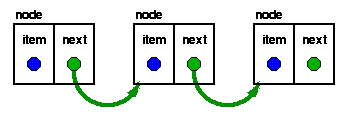
כל
חוליה (node) ברשימה מכילה שני רכיבים:
·
נתון המאוחסן
ברשימה.
·
מצביע לנתון
הבא ברשימה.
החוליה האחרונה
ברשימה מכילה מצביע ל- NULL, על מנת לציין כי זהו
סוף (או זנב) הרשימה.
כאשר נוסף נתון
לרשימה, מוקצה דינאמית זיכרון עבור חוליה. לכן, מספר הנתונים שניתן להוסיף לרשימה
מוגבל רק על ידי כמות הזיכרון הזמין.
טיפול
ברשימה
המשתנה אשר
מייצג את הרשימה הוא פשוט המצביע לחוליה שבראש הרשימה.
הוספה
לרשימה
האסטרטגיה
הפשוטה ביותר להוספת נתון לרשימה היא:
·
הקצאת שטח עבור
חוליה חדשה.
·
העתקת הנתון
לתוך החוליה.
·
קביעת המצביע (next) של החוליה החדשה כמצביע לחוליה שהייתה עד כה בתחילת הרשימה.
·
קביעת ראש
הרשימה כמצביע לחוליה החדשה.
אסטרטגיה זו
היא מהירה ויעילה, אך השימוש בה מוסיף כל נתון לתחילת הרשימה.
אלטרנטיבה לכך
היא יצירת מבנה עבור הרשימה, המכיל גם את ראש וגם את זנב הרשימה:
struct fifo_list { struct node *head; struct node *tail; };
הקוד עבור AddToCollection מותאם בקלות כך
שתיווצר רשימה אשר בה נתון חדש מוכנס לסוף הרשימה. ההגדרות נשארות זהות לאלה אשר
נעשה בהם שימוש ביישום מערך: מפרמטר max_item ב- ConsCollection פשוט מתעלמים.
כך, אנו צריכים
רק לשנות את דרך הביצוע, בלא שיידרש כל שינוי ביישומים העושים שימוש באובייקט זה.
ההשלכות החיוביות לגבי עלות אחזקת התוכנה באופן זה הן משמעותיות.
מבנה הנתונים
משתנה, אך מאחר שהפרטים (מאפייני האובייקט, האלמנטים של המבנה) מוסתרים מהמשתמש,
אין לכך כל השפעה על המשתמש.
נקודות
לתשומת לב:
·
יישום זה של
אוסף הנתונים שלנו יכול להוות תחליף ליישום הקודם ללא כל שינוי בתוכנית הלקוח.
מלבד היוצא מן הכלל של הגמישות הנוספת, כך שכל מספר של נתונים יכול להתווסף לאוסף
הנתונים, יישום זה מספק בדיוק את אותה רמה גבוהה של פעולה שסיפק היישום הקודם.
·
יישום הרשימה
המקושרת מוותר על יעילות לטובת גמישות, ולרוב הקריאה של המערכת להקצאת זיכרון היא
יקרה יחסית. לרוב, ההקצאה המוקדמת ביישום המערך יעילה יותר (לחץ כאן להשוואה בין רשימות למערכים)
דוגמאות נוספות לחליפין כזו
(יעילות תמורת גמישות) נראה בהמשך.
הלימוד של מבני
הנתונים והאלגוריתמים השונים יאפשר לך להחליט איזה יישום לבחור כך שיתאים לדרישות המשתמש.
3.2.2
סוגי רשימות
רשימה
מקושרת מעגלית (Circularly Linked List)
על ידי שמירה
על כך שזנב הרשימה תמיד מצביע לתחילת הרשימה, אנו יכולים לבנות רשימה מקושרת
מעגלית. אם המצביע החיצוני (זה שב-struct t_node ביישום שלנו) מצביע לזנב הנוכחי של הרשימה, אזי ראש
הרשימה יכול להימצא בקלות על ידי tail->next, דבר המאפשר לנו הן
רשימות LIFO והן רשימות FIFO בעזרת מצביע חיצוני אחד. מספר הבתים הנחסכים בדרך זו הוא מועט ולא
נחשב למשמעותי במעבדים חדשים. השימוש בסוג זה של רשימות מצוי יותר ביישומים
הדורשים עיבוד
"round-robin".
רשימה
מקושרת כפולה (Doubly Linked List)
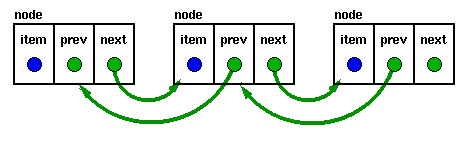
לרשימה שכזו יש
מצביע גם לפריט הקודם ולא רק לפריט הבא. הדבר מאפשר סריקה או חיפוש ברשימה בשני הכיוונים
(על מנת לחזור לאחור ברשימה רגילה יש צורך לחזור לתחילת הרשימה ולסרוק משם קדימה).
יישומים רבים דורשים חיפושים הן קדימה והן אחורה בחלקים מסוימים של רשימה. לדוגמא,
חיפוש של שם נפוץ כגון "קים" בספר טלפונים קוריאני ידרוש חיפוש רב אחורה וקדימה באזור קטן של הרשימה, כך שקישורים
לאחור עשויים להיות חשובים ביותר. במקרה כזה, מבנה החוליה יהיה שונה ויכיל שני
קשרים:
struct t_node {
void *item; struct t_node *previous; struct t_node *next; } node;
רשימות
במערכים
למרות שזה נראה
חסר טעם (מדוע לכפות על מערך מבנה שבו קיימים מצביעי "next" ?),
זה בדיוק מה שעושים מקצי הזיכרון
(memory allocators) - תוכניות האחראיות על הקצאת
זיכרון, על מנת לנהל שטח פנוי. זיכרון הוא רק מערך של מילים. לאחר סדרה של הקצאות
זיכרון וביטול של הקצאות זיכרון, ישנם גושים של זיכרון פנוי המפוזרים לאורך
הזיכרונות המוקצים. במטרה לאפשר שימוש מחדש בזיכרון זה, מקצי הזיכרון יקשרו בדרך
כלל יחד גושים פנויים לרשימה פנויה בעזרת מצביע בכל גוש פנוי אל הגוש הפנוי הבא.
מצביע חיצוני יצביע לגוש הראשון ברשימה פנויה זו. כאשר גוש חדש של זיכרון מבוקש,
מקצה הזיכרון סורק בדרך כלל את הרשימה הפנויה, תוך חיפוש אחר גוש חופשי בגודל
המתאים, וכשגוש כזה נמצא הוא מוחק אותו מהרשימה הפנויה (הרשימה מקושרת מחדש מסביב
לגוש שנמחק).
מושגים
מבנה
נתונים דינאמי
מבנה אשר גדל או קטן בהתאם לשינוי כמות הנתונים אשר הוא
מאחסן. רשימות, מחסניות
ועצים הם כולם מבני נתונים דינאמיים.
המשך ל: מחסניות חזור
ל: תוכן עניינים