11. קידוד הופמן
מבנה נתונים
ואלגוריתמים
בעיה זו הינה
מציאת האורך המינימלי של מחרוזת סיביות אשר יכולה לשמש לקידוד מחרוזת של סימנים.
יישום אחד של בעיה זו הוא דחיסת טקסטים: מהו המספר המינימלי של סיביות (ולכן הגודל
המינימלי של קובץ) המאפשר לאחסן קטע שרירותי של טקסט?
סכמת הופמן משתמשת
בטבלת השכיחויות של הופעת כל סימן (או תו) בקלט. ניתן ליצור טבלה זו מהקלט עצמו או
מנתונים אשר מייצגים את הקלט. לדוגמא, שכיחות ההופעה של אותיות באנגלית רגילה
עשויה להיות מוסקת מעיבוד מספר גדול של מסמכי טקסט, ולאחר מכן ניתן לנצל מידע זה
לטובת קידוד כל מסמך טקסט. צריך להקצות מחרוזת סיביות באורך משתנה לכל תו, אשר
מייצגת אותו באופן חד משמעי. דבר זה אומר כי הקידוד עבור כל תו חייב להיות בעל
קידומת ייחודית. אם התווים הנדרשים לקידוד מסודרים בעץ בינארי, אזי הקידוד עבור כל
תו נמצא על ידי מעבר על העץ מהשורש עד לתו שבעלה. הקידוד הוא מחרוזת הסימנים בכל
ענף שעליו עוברים.
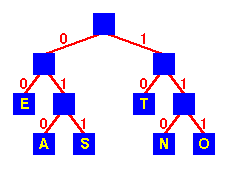
לדוגמא:
מחרוזת קידוד
TEA 10 00 010
SEA 011 00 010
TEN 10 00 110
עץ קידוד עבור ETASNO
הערות:
1. כפי שרצוי, האותיות בעלות השכיחות הגבוהה
ביותר - E ו- T
הן בעלות שתי ספרות קידוד, בעוד שלכל שאר האותיות יש שלוש ספרות קידוד.
2. הקידוד ייעשה בעזרת טבלת תרגום.
גישת הפרד
ומשול תגרום לנו לשאול איזה אותיות תופענה בתתי-העצים הימניים והשמאליים, ולנסות
לבנות את העץ מלמעלה למטה. כמו עם עץ חיפוש בינארי אופטימליים, דבר זה יוביל
לאלגוריתם בזמן מעריכי.
גישה חמדנית
תמקם את n התווים ב- n תתי-עצים, ותתחיל בצירוף שני הצמתים בעלי המשקל הנמוך ביותר לתוך
עץ, שיקבל את סכום המשקלים של שני העלים כמשקל השורש.
זמן הסיבוכיות
של אלגוריתם הופמן הוא O(nlogn). על ידי שימוש בערמה על מנת לאחסן את המשקל של כל
עץ, כל איטרציה דורשת זמן של O(logn)
על מנת לקבוע מהו המשקל הנמוך ביותר ולהכניס את המשקל החדש.
ישנן O(n) איטרציות - אחת עבור כל פריט.
פענוח של מידע מקודד
הסקרנים מבינכם
שואלים כעת: "כיצד נפענח את מחרוזות הסיביות שקודדו על ידי קידוד הופמן? כיצד
נעבור ממחרוזות מקודדות באורכים שונים לתווים?
הליך הפענוח
הוא פשוט באופן מפתיע. החל מהסיבית הראשונה, משתמשים בסיבית הבאה שבזרם הקלט על
מנת לקבוע האם ללכת שמאלה או ימינה בעץ הפענוח. כאשר מגיעים לעלה בעץ, פענחנו תו,
ואנו מכניסים אותו (בצורה הלא דחוסה) אל תוך זרם הפלט. הסיבית הבאה של זרם הקלט
היא הסיבית הראשונה של התו הבא.
הדיאגרמה הבאה
ממחישה את הליך הפענוח:
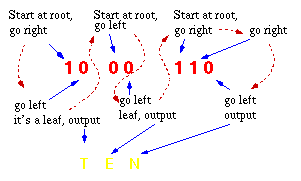
העברה ואחסון של מידע המקודד בקידוד הופמן
אם המערכת מטפלת
באופן מתמשך במידע שבו לסימנים השונים שכיחות הופעתה דומה, אז
הן המקודדים
והן המפענחים יכולים להשתמש בטבלת קידוד סטנדרטית או עץ פענוח סטנדרטי. בכל אופן,
אפילו מידע טקסטואלי ממקורות מגוונים הוא בעל מאפיינים שונים. לדוגמא, כשמדובר
בטקסט אנגלי רגיל שורש העץ יהיה בדרך כלל 'e',
ויהיה קידוד קצר עבור 'a' ו- 't',
בעוד שכשמדובר בתוכניות בשפת C השורש יכיל לרוב את
הסימן ';'
ויהיה קידוד קצור עבור סימני פיסוק נוספים כגון ')' ו- '('.
אם המידע מכיל סדרות נתונים עם שכיחויות משתנות, אזי לצורך קידוד אופטימלי יש
ליצור עץ קידוד עבור כל סדרת נתונים ולאחסן או להעביר את הקידוד עם המידע. משמעות
העלות הנוספת של העברת עץ הקידוד היא כי לא נרוויח רווח כולל אלא אם זרם המידע
המקודד היא ארוך יחסית, כך שהחיסכון מהדחיסה יפצה (ויותר מכך) על עלות ההעברה
הנוספת של עץ הקידוד.
|
|
|
קוד לדוגמא
מימוש מלא של
אלגוריתם הופמן נמצא ב- Verilib כרגע ישנה שם גרסה ב- Java.
גרסאות ב- C וב- C++
יתווספו בהמשך.
בעיות אחרות - תבנית מיזוג
אופטימלית
נניח כי יש לנו
סדרת קבצים בגדלים שונים שעלינו למזג. באיזה סדר וצירופים אנו אמורים למזגם?
הפתרון לבעיה זו דומה בעיקרון לאלגוריתם הופמן - עץ המיזוג נבנה מהקובץ הגדול
ביותר, אשר בשורש שלו.
המשך ל: טרנספורמציות פורייר מהירות חזור
ל: תוכן עניינים